question
- translation invariance是指什么,有什么作用
- 其中一种loss:IoU —— Intersection of Union
- Ground Truth
-
3.
convnet = h w d (height, width, color channel)
基于translation invariance
三种技术
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
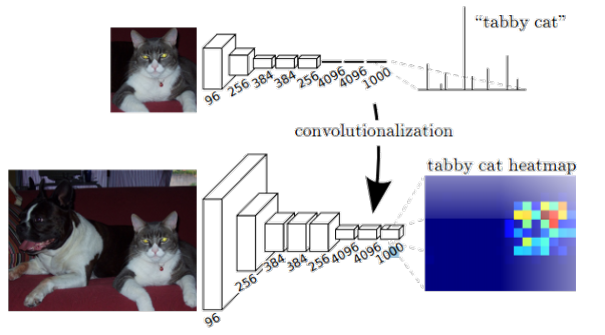
卷积化
FC换成Conv以保留图像的空间信息
上采样
此处的上采样即是反卷积(Deconvolution)。当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。CS231n这门课中说,叫conv_transpose更为合适。
Loss
对于最终输出的每一个像素的类别信息,我们并不把所有的像素点的结果计算到loss中进行反向传播,而是只取其中一部分的像素点。这个想法是有点道理的,因为每一个紧密相邻的像素点之前的特征差距可能并不大,如果每一个像素点都计算在内,那么就相当于我们对某一组特征增加了很高的权重。但好在我们对所有像素点都增加权重的话,这个影响还是会抵消的。