卷积操作
$O$是output_shape,$W$是image,$K$是filter,$P$是padding,$S$是stride
stride = 1
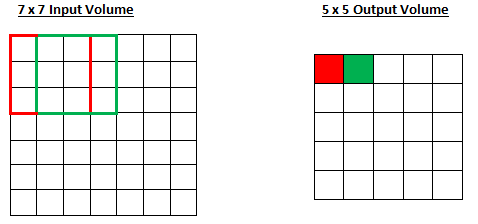
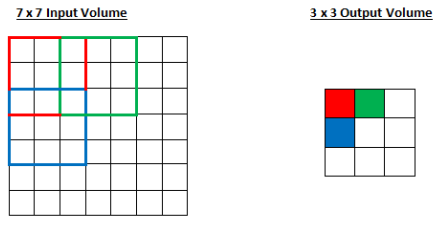
stride = 2
Padding
- padding的计算公式与conv一样
- zero padding
有这些情况会使用zero padding
- 卷积后image尺寸很小,但我们又想使用conv
- 由于image尺寸跟filter尺寸的原因

pooling
也叫downsampling(下采样)层,最常用的是max-pooling
stride = 2

ReLu
优点:
- 因为它在准确度不发生明显改变的情况下能把训练速度提高很多
- 能够减轻vanishing gradient problem
—指梯度以指数方式在层中消失,导致网络较底层的训练速度非常慢 - 把negative activation变为0,增加了模型的非线性特征,而且不影响感受域
参见 Geoffrey Hinton(即深度学习之父)的论文:Rectified Linear Units Improve Restricted Boltzmann Machines
Dropout
随机丢弃神经元,简单来说,就是在训练过程中在Dropout层设置一个随机的激活参数集,在forward pass中将这些激活参数集设置为0。
理解了大概,这部分细节需要详细看看