Intro
- 论文及源代码:点击这里
若发现存在错误,欢迎指正。
GCN,是基于Spectral Graph Theory所研究出来的一种方法,它主要的好处是利用了SGT里面一些已有的结论和方法,来得到图的性质。GCRN是一个将GCN和RNN结合起来使用的模型,能处理具有空间和时序的数据。
源代码的目录结构:
1 | gconvRNN |
在源码中,GCRN用于预测单词字符序列
本文从三个方面讲解GCRN源码的处理思路
- 数据预处理
- GCRN实现思路
- 开始训练
- 代码附录
数据预处理:
train\valid\test 数据集的格式都是一样的:
a e r b a n k n o t e b e r l i t z c a l l o w a y c e n t r u s t c l u e t t f r o m s t e i n g i t a n o g u t e r m a n h y d r o - q u e b e c i p o k i a m e m o t e c m l x n a h b p u n t s r a k e r e g a t t a r u b e n s s i m s n a c k - f o o d s s a n g y o n g s w a p o w a c h t e r
p i e r r e < u n k > N y e a r s o l d w i l l j o i n t h e b o a r d a s a n o n e x e c u t i v e d i r e c t o r n o v . N
m r . < u n k > i s c h a i r m a n o f < u n k > n . v . t h e d u t c h p u b l i s h i n g _ g r o u p
UNK- “unknown token” - is used to replace the rare words that did not fit in your vocabulary. So your sentenceMy name is guotong1998will be translated intoMy name is _unk_
1. 将句子按字典映射成数字序列
1 | for every sentences: |
例如:
p i e r r e < u n k > N y e a r s o l d w i l l j o i n t h e b o a r d a s a n o n e x e c u t i v e d i r e c t o r n o v . N |
[24, 10, 1, 2, 2, 1, 3, 27, 15, 5, 6, 28, 3, 29, 3, 14, 1, 0, 2, 16, 3, 7, 9, 21, 3, 13, 10, 9, 9, 3, 30, 7, 10, 5, 3, 8, 20, 1, 3, 4, 7, 0, 2, 21, 3, 0, 16, 3, 0, 3, 5, 7, 5, 1, 25, 1, 12, 15, 8, 10, 31, 1, 3, 21, 10, 2, 1, 12, 8, 7, 2, 3, 5, 7, 31, 32, 3, 29, 26]
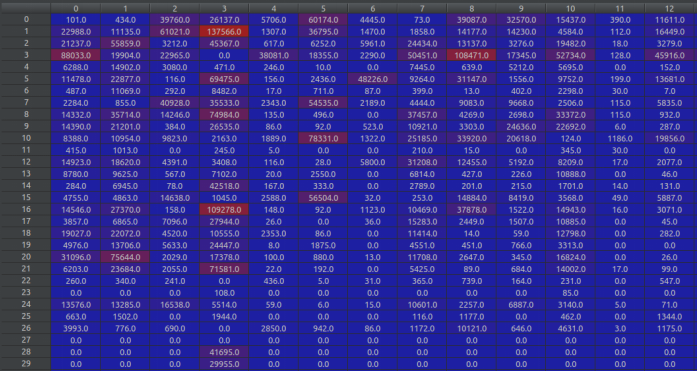
2. 构造邻接矩阵
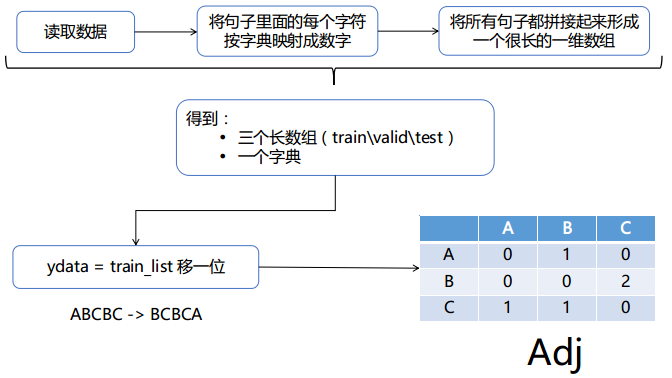
得到邻接矩阵的值:
GCRN实现思路:
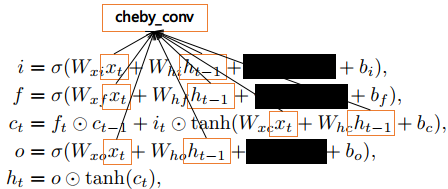
GCRN = GCN + RNN。
公式:
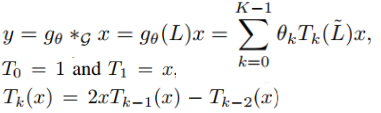
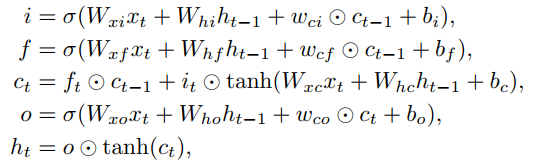
但是 代码中的实现方式稍有不同
GCN :
每次得到的 $T_k(x)$ 都与x做concat,最后得到的x与W相乘
LSTM :
开始训练
数据预处理 -> model定义 -> train
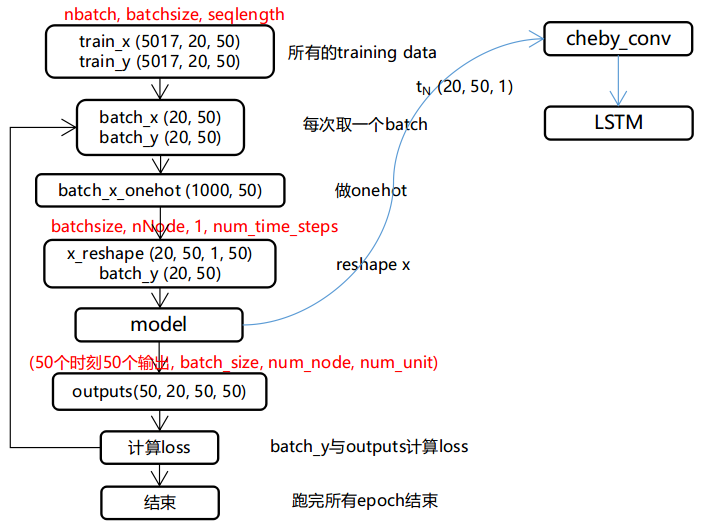
输出ouput的shape为(batch_size, num_node, num_unit) —— (20, 50, 50)。由于设置了有50个LSTM units,所以这里需要使所有units的输出做线性变换,使其变为一个值:
prediction = output * W -b,这里的prediction的shape为(20, 50, 1)
那么,所有时刻的输出的shape为(50, 20, 50, 1)
代码
GCN实现方法
1 | def cheby_conv(x, L, lmax, feat_out, K, W): |
LSTM实现方法
1 | def __call__(self, inputs, state, scope=None): |
其他变量
| 变量 | shape | meaning |
|---|---|---|
| rnn_input | (20, 50, 1, 50) | (batch_size, num_node, feat_in, num_time_steps) |
| rnn_input_seq | (20, 50, 1) * 50 | (batch_size, num_node, feat_in) * num_time_steps |
| rnn_output | (20, 50) | (batch_size, num_time_steps) |
| rnn_output_seq | (20) * 50 | (batch_size) * num_time_steps |
| num_hidden | 50 | 隐藏层单元 |
| x_batches | (5017, 20, 50) | [-1, batch_size, seq_length] |
| y_batches | (5017, 20, 50) | [-1, batch_size, seq_length] |
| outputs | (50, 20, 50, 50) | (50个时刻50个输出, batch_size, num_node, num_unit) |
| output | (20, 50, 50) | outputs的单个时刻输出(batch_size, num_node, num_unit) |
Laplacian matrix
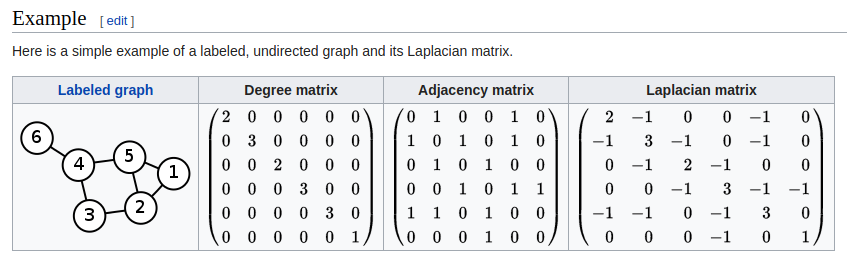
Properties
对一个无向图$G$和他的laplacian matrix $L$,有特征值$\lambda_0 \leq \lambda_1 \leq \lambda_2 …$:
- L是对称的
- L是半正定的(即所有$\lambda_i > 0$),这可以在关联矩阵部分验证,也同样可以从Laplacian是对称并且对角占优(diagonally dominant)得出
- L是M-matrix(它的非对角线上的项是负的,但它的特征值的实部为负)
- 行或列相加结果为0
- L的最小非零特征值称为谱间隙(spectral gap)
- 图中连通分量的个数是拉普拉斯算子的零空间维数和0特征值的代数多重性
- 拉普拉斯矩阵是奇异的
问题
- 代码实现里面的公式跟论文是否真的不一样
- x2 = 2 * tf.sparse_tensor_dense_matmul(L, x1) - x0 起到一个什么作用
后记
补充一下,后来跟实验室的小伙伴谈论过后对GCN有了比较深刻的认识。上面问题中的第二点,其实跟GCN的K的大小有关。K=1,表示包含了该节点一条的信息。至于为什么会这样,这是因为在计算过程中与由adj mnatrix得来的Laplacian相乘,每乘一次,就会多包含一跳的节点信息。